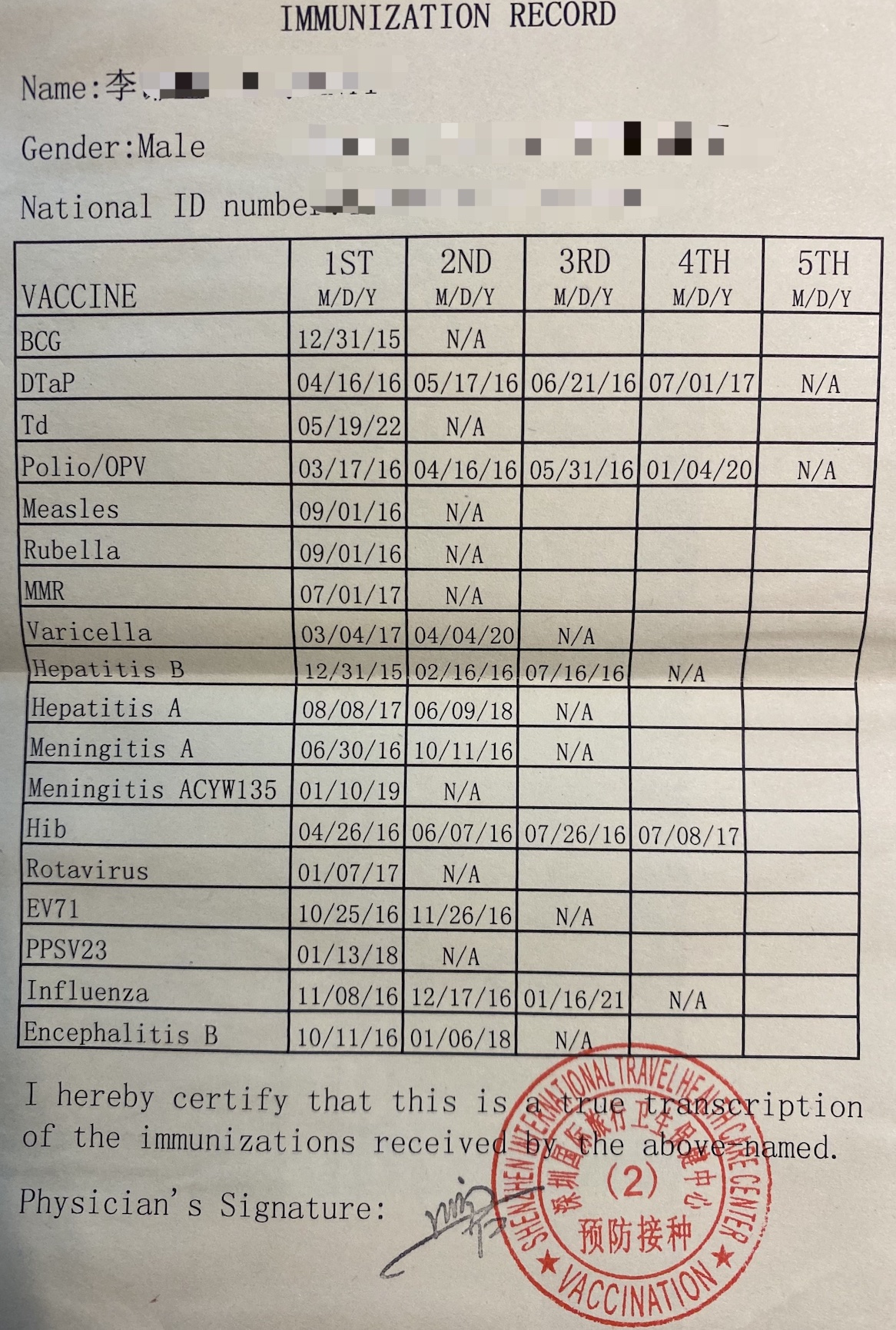
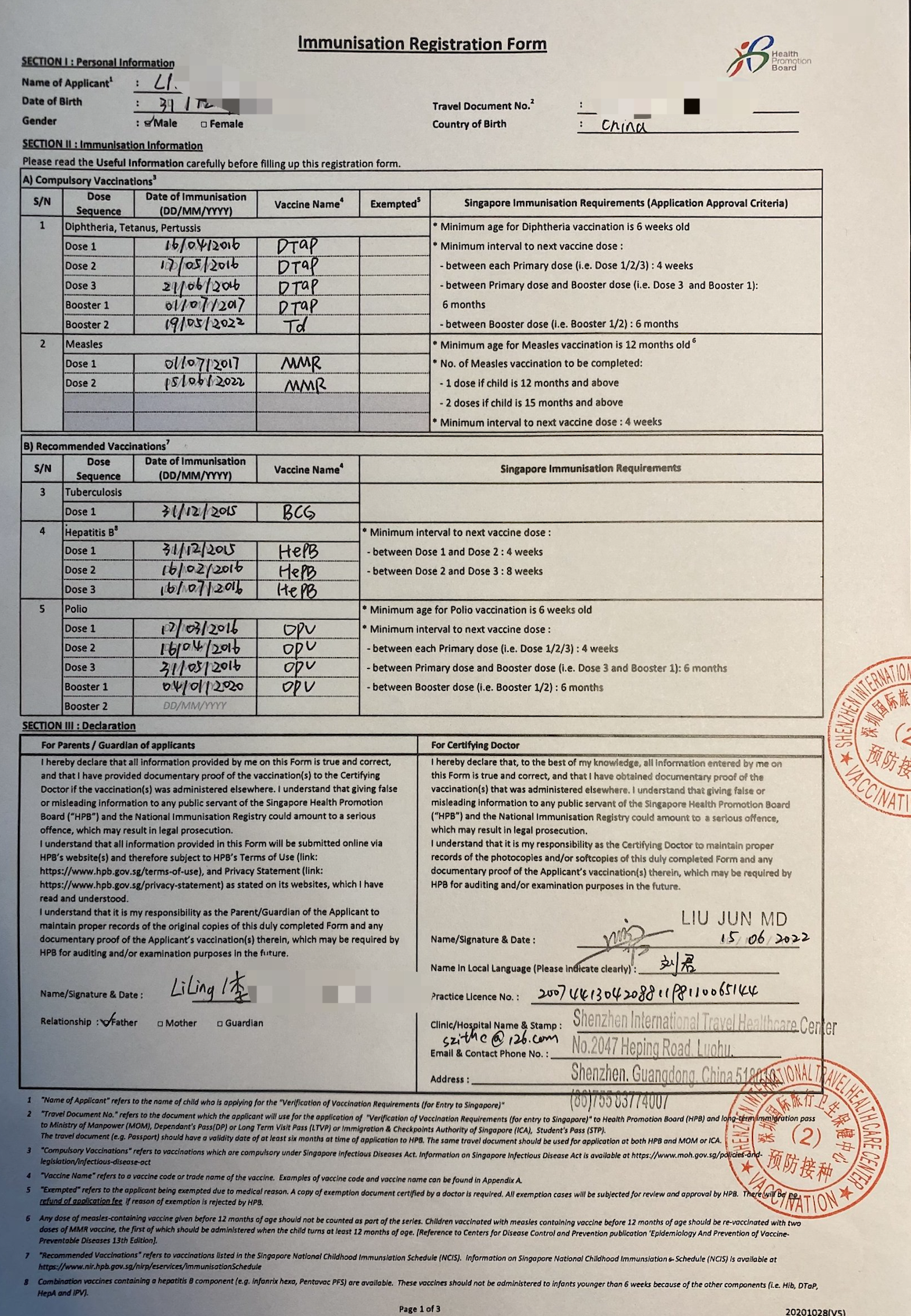
带孩子去新加坡的话,一般都是DP家属签证或者学生签证,无论那种都是需要在新加坡的HPB网站办理一个疫苗公证(又叫 VERIFICATION OF VACCINATION),然后才能申请签证,简单来说就是上传一系列的PDF,再缴30新币,得到下图PDF文件,这个PDF是申请家属签证必须提供的材料,而且一般代理办EP的也不会帮你申请,需要自己申请。
Many projects often need a search engine, but for Chinese content, we can not simply use MySQL like to search, especially for the professional field Chinese sentence search, we need specialized words from corpus to bring better search result, because the Chinese words are not split with spaces, which requires us to do two things.
1 Extract specialized words/vocabulary from corpus existed, such as brand, character names, you can also polish your dict manually.
2 Import that specialized vocabulary into the search engine and the search engine(Elasticsearch) can index those keywords split by IK analyzer.
How directory looks like is below We need download elasticsearch-analysis-ik-7.11.2.zip and unzip it in directory plugin as we mapped it in volumes in file docker-compose.yml
Cosmetics.dic is the file that contains Chinese word that need to be tokenized. here is the example of some cosmetics brands
1 2 3 4
烟酰胺 抗蓝光 康萃乐 怡丽丝尔
Segmentation (get Cosmetics.dic from corpus)
Here we need Jieba Segmentation Tool which is intent to built the best Python Chinese word segmentation module. corpus need to be ready in with txt format. the corpus should contains specialized Chinese words
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--Users can configure their own extended dictionary here--> <entry key="ext_dict">/root/plugin/ik/config/huazhuangping.dic</entry> <!--Users can configure their own extended stop word dictionary here--> <entry key="ext_stopwords"></entry> <!--Users can configure the remote extension link here --> <entry key="remote_ext_dict">https://xxxxxx/word_for_elasticsearch.txt</entry> <!--The user can configure the remote extension stop word dictionary here--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
Suppose we are creating a search engine for ecommercial with field Id,product_desc and product_desc is the field that we want to search with full-text.
local data = 'wait to be encrypted' local key = '01234567890123456'--length is 16 local mc_ecb = require("resty.ecb_mcrypt") local ecb = mc_ecb:new(); local enc_data = ecb:encrypt(key,data ); ngx.print(enc_data) -- you must use 'ngx.print' rather then 'ngx.say' -- while 'ngx.say' append a '\n' at the end of string
functionutf8.charbytes(s, i) -- argument defaults i = i or1 local c = string.byte(s, i) -- determine bytes needed for character, based on RFC 3629 if c > 0and c <= 127then -- UTF8-1 byte return1 elseif c >= 194and c <= 223then -- UTF8-2 byte return2 elseif c >= 224and c <= 239then -- UTF8-3 byte return3 elseif c >= 240and c <= 244then -- UTF8-4 byte return4 end end
Unicode & UTF8 convert method
Unicode code range
UTF-8 code
example
hex code
binary code
char
0000 0000-0000 007F
0xxxxxxx
n(alphabet)
0000 0000-0000 007F
110xxxxx 10xxxxxx
ñ
0000 0080-0000 07FF
1110xxxx 10xxxxxx 10xxxxxx
你(most CJK)
0001 0000-0010 FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
other chars
but we should pay attention to 4 bytes UTF8[emoji], it works not that simple
special Method
javascript engine using UTF16,characters in Basic Multilingual Plane were the same with unicode, but if the characters were in Supplementary Plane it should use the formula below,usually we encounter Supplementary Plane emoji like😝 (4 byte UTF8 character)
1 2 3
-- formula 1 H = Math.floor((c-0x10000) / 0x400)+0xD800 L = (c - 0x10000) % 0x400 + 0xDC00





 ]
]